기술통계
- 데이터 분석 목적으로 수집된 데이터를 확률/통계적 정리/요약하는 기초적 통계
회귀 분석 모형
- 단순 회귀 : 독립변수과 종속변수 1개씩, 모두 수치형
- 다중 회귀 : 2개 이상 독립변수이고 수치형/범주형, 1개 수치형은 종속변수
회귀 분석 모형의 적합성
- 회귀식의 통계적 유의성 평가 : 분산 분석표
- 모형이 잘 설명하는지 확인 : 결정계수
- 전제조건 [등선정독비] : 등분산성, 선형성, 정규성(정상성), 독립성, 비상관성 => 잔차 그래프로 확인
회귀모델의 독립변수 선택방법
- 전진 선택법 : 종속변수에 큰 영향 주는것부터 하나씩 독립변수로 만듦
- 후진 제거법 : 모든 독립변수부터 시작해서, 중요하지 않은 독립변수값은 차례대로 제거
- 단계적 방법 : 주로 사용, 전진 선택법+후진 제거법 절충안
분산 분석(ANOVA)
- 2개 이상 집단 비교 시에 집단내 분산, 총 평균과 각 집단의 평균 차이에 의해 생긴 집단간 분산 비교로 얻은 F분포 이용해 가설검정
- F 검정 통계량 : 집단 내 분산 대비 집단간 분산이 몇개 더 큰지를 나타내는 값
분산 분석 종류
- 일원분산 분석 : 독립/종속변수 1개씩
- 이원분산 분석 : 독립변수 2개, 종속변수 1개
- 다변량 분산 분석 : 종속변수 2개 이상
주성분 분석
- 기존 변수의 분산/공분산 패턴을 축약한 주성분 변수를 원래 변수의 선형결합으로 추출하는 통계기법
판별 분석
- 집단을 구별할 수 있는 판별규칙 만들어, 새로운 개체가 어느 집단인지 탐색하는 통계기법
표본 추출 기법 [단계층군]
- 단순 무작위 추출 : 규칙없이 표본 추출
- 계통 추출 : 일정 간격으로 추출 ex)끝자리가 7인 사람
- 층화 추출 : 계층 나누고, 계층별 무작위 추출 ex) 지역을 도로 나누고, 도에서 무작위 추출
- 군집 추출 : 군집 나누고 추출
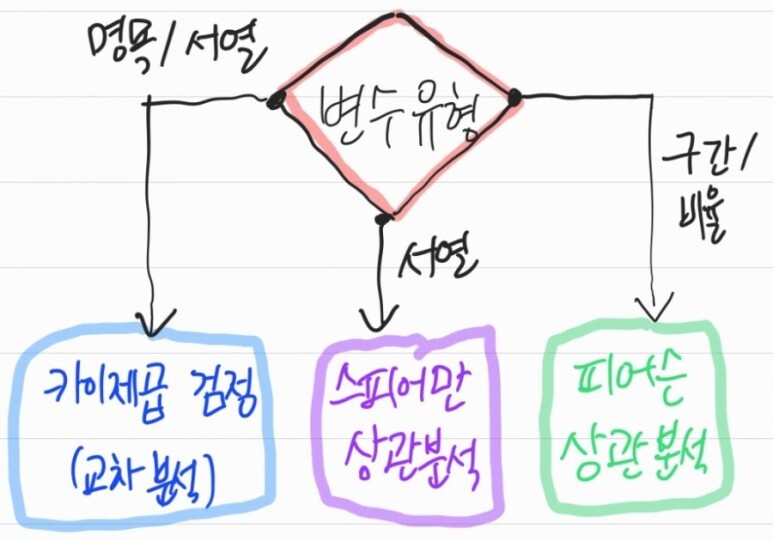
데이터 척도
- 질적 속성 : 명목 척도, 순서 척도
- 양적 속성 : 구간(등간) 척도, 비율 척도
이산확률분포 종류 [포베이]
- 포아송 분포 : 주어진 시간/영역에서 어떤 사건 발생횟수를 나타내는 확률분포
- 베르누이 분포 : 실험결과가 성공 또는 실패 중 하나를 얻는 확률분포
- 이항분포 : n번 시행 중에 k번 성공할 확률분포
연속확률분포 종류 [카표준TF] ; 카~표정이 맞거나 틀리거나
- 카이제곱 분포
- 표준정규분포(z-분포)
- 정규분포
- T 분포 : 정규분포 평균 해석에 많이 사용
- F 분포
'빅데이터분석기사' 카테고리의 다른 글
| [빅분기-필기요약] 8. 빅데이터 모델링 > 분석기법 적용 (1) | 2023.04.08 |
|---|---|
| [빅분기-필기요약] 7. 빅데이터 모델링 > 분석 모형 설계 (0) | 2023.04.08 |
| [빅분기-필기요약] 5. 데이터 탐색 (0) | 2023.04.08 |
| [빅분기-필기요약] 4. 데이터 전처리 (0) | 2023.04.08 |
| [빅분기-필기요약] 3. 데이터 수집 및 저장 계획 (0) | 2023.04.08 |