데이터 수집 프로세스
1. 필요한 수집 데이터 도출
2. 데이터 목록 작성
3. 데이터 소유기관 파악 및 협의
4. 데이터 유형 분류 및 확인
5. 수집 기술 선정
6. 수집 계획서 작성
7. 수집 주기 결정
8. 데이터 수집 실행
정형 데이터 수집 방식/기술
- ETL : 추출 > 변환 > 적재 => DW, DM
- FTP : TCP/IP 기반, active/passive FTP
- DB to DB : DB간 동기화
- Rsync : 파일과 디렉토리 동기화
- 스쿱 : RDBMS에서 하둡으로 데이터 전송, 전송 병렬화, 프로그래밍 방식의 인터렉션, 벌크 임포트
반정형 데이터 수집 방식/기술
- 센싱
- 스트리밍
- 플럼 : pub/sub 구조, pull 방식, 파일기반 저장방식, 소스/채널/싱크로 구성
- 스크라이브
- 척와 : 분산된 서버의 에이전트 실행 > 컬렉터가 데이터 수집 > 싱크는 임시저장 역할, 청크 단위 전송
비정형 데이터 수집 방식/기술
- 크롤링
- RSS : 새로 게시된 글 공유, XML 기반
- Open API : 실시간 데이터 송수신
- 스크래파이(scrapy) : 파이썬 기반
- 아파치 카프카 : 대용량 실시간 로그 처리, 스트리밍 플랫폼, 생상자/소비자/카프카 클러스터
데이터 속성
- 범주형(질적 변수) : 명목형, 순서형
- 수치형(양적 변수) : 연속형, 이산형
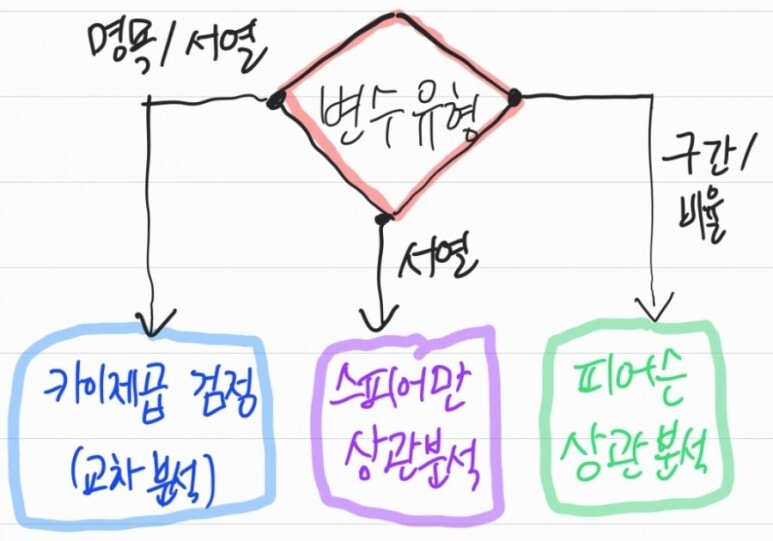
데이터 측정 척도 [명순구비]
- 명목 척도 : 값은 의미만 가짐, 혈액형
- 순위 척도(서열 척도) : 값이 서열을 의미, 맛집 평점
- 구간 척도(등간/간격/거리 척도) : 동일 간격으로 차이 비교, 미세먼지 수치
- 비율 척도 : 절대 영점 있음, 순서와 의미가 모두 있음, 나이/키
데이터 변환 기술
- 평활화 : 잡음을 제거를 위한 이상값 제거, 데이터를 매끄럽게 변환
- 집계 : 그룹 연산 수행
- 일반화 : 스케일링, 범용적 데이터로 변환
- 정규화 : 정해진 구간내로 변환 (최소-최대 정규화, z-스코어 정규화, 소수점 정규화)
- 속성 생성 : 속성이나 특성을 이용해 일반화
데이터 비식별화 처리 기법 [가총범삭마]
- 가명처리 : 휴리스틱 익명화, K-익명화, 암호화, 교환(swaping)
- 총계처리 : 단순집계, 부분집계, 라운딩(올림,내림), 데이터 재배열
- 범주화 : 단순평균, 랜덤 올림/절사, 분포/구간 표현 등
- 삭제 : 속성값 삭제, 데이터 행 삭제 등
- 마스킹 : 임의 잡음값 추가, 공백/대체
데이터 품질 특성
- 유효성 [일정]
> 일관성 [일정무] : 일치성, 정합성, 무결성
> 정확성 [필연적사정] : 필수성, 연관성, 적합성, 사실성, 정확성
- 활용성 [유접적보]
> 유용성 : 충분성, 유연성 사용성, 추적성
> 접근성
> 적시성
> 보안성
데이터 변환후 품질 검증 프로세스
- 빅데이터 수집 > 메타 데이터 수집 > 메타 데이터 분석 > 데이터 속성 분석
빅데이터 적재 소프트웨어 아키텍처 정의
- 수집 : 크롤러, ETL, 연계/수집 플랫폼
- 적재 및 저장 : 데이터 구성 플랫폼, RDB, NoSQL, Object 스토리지, 빅데이터 자원관리
- 분석 : 빅데이터 분석 모델, 분석 플랫폼
- 활용 : 데이터 시각화, 데이터 활용 플랫폼, Open API 서비스
데이터 적재 도구
- Fluentd, 플럼, 스크라이브, 로그스태쉬(logstash)
데이터 저장 기술
- 분산 파일 시스템, 데이터베이스 클러스터, NoSQL, 병렬 DBMS, 네트워크 구성 저장 시스템, 클라우드 파일 저장 시스템
구글 파일 시스템(GFS)
- 파일을 청크단위(64MB) 나눠, 여러 복제본을 청크서버에 분산/저장
- 클라이언트(posix 미지원), 마스터, 청크 서버로 구성
- 클라이언트가 GFS 마스터에 파일 요청 > 마스터는 청크의 매핑정보 찾아서 해당 청크 서버에 전송 요청 > 해당 청크 서버는 클라이언트에서 청크 데이터 전송
하둡 분산 파일 시스템(HDFS)
- 블록 구조의 파일시스템
- 1개 네임노드 : 메타데이터 관리, 마스터 역할, 데이트 노드로 하트비트 받아 노드상태/블록상태 체크
- 1개 이상 보조 네임노드 : HDFS 상태 모니터링, 네임노드의 주기적 스냅샷
- N개 데이터 노드 : 슬레이브 노드, 데이터 입출력 처리, 3중 복제 저장
러스터
- 객체 기반 클러스터 파일 시스템
- 계층화된 tcp/ip, 인피니밴드 지원
- 클라이언트 파일 시스템(고속 네트워크 연결), 메타데이터 서버, 객체 저장 서버로 구성
데이터베이스 클러스터
- 공유 디스크 클러스터(ex.RAC), 무공유 클러스터(ex. galera)
NoSQL
- schemaless, 조인연산 x, 수평적 확장 가능, BASE, CAP 이론에서 2개 속성만 만족
- Key-value(redis, dynamoDB), Column Family(cassandra, HBase), Document(mongdb, couchbase), Graph(neo4j, allegroGraph)
BASE
- Basically Available : 언제든 데이터 접근 가능, 분산 시스템이라 가용성 의미
- Soft state : 특정 시점에 일시적 일관성 미보장, 외부 전송된 정보로 노드상태 결정
- Eventaully consistency : 결국 일관성을 마춰짐
CAP 이론
- Consistency(일관성), Availability(가용성), Partition Tolerance(분산 가능) 에서 2가지만 만족
- C + A => RDBMS
- A + P => NoSQL
- C + P => NoSQL